- Home
- Computing
Computing
About
News, reviews, and discussion about desktop PCs, laptops, and everything else in the world of computing, including in-depth buying guides and daily videos.


The Razer Blade RTX 40 series gaming laptops are on sale right now










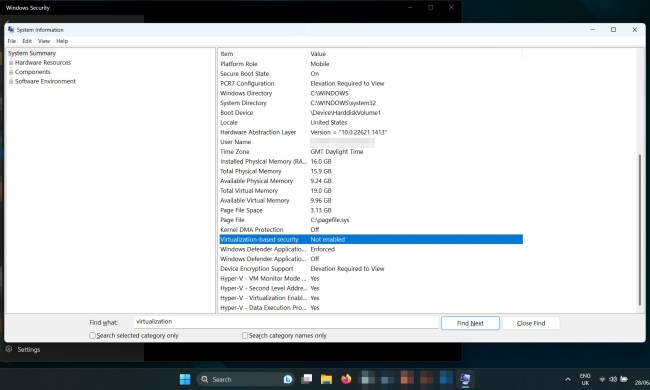
How to disable VBS in Windows 11 to improve gaming

How to do hanging indent on Google Docs

LG just knocked $300 off this 16-inch lightweight laptop

How to download a video from Facebook




How to delete Slack messages on desktop and mobile

I finally found a gaming laptop utility that’s actually worth using

How to download Vimeo videos on desktop and mobile

Hurry! The Razer Blade 17 gaming laptop is 44% off today

How to dual boot Linux and Windows

How to change mouse DPI on Windows and Mac

How to choose an external hard drive

Meta has a bold new strategy for VR

Alienware m16 R2 vs. Alienware x16 R2: Which 16-inch model is better?

Buying a Steam Deck has never been cheaper

The Vision Pro is already in trouble. Here’s how Apple can turn the tide

The MSI Claw just got both faster and cheaper

VR is even cheaper: Meta Quest 2 just got a price reduction

Some Intel CPUs lost 9% of their performance almost overnight

Quick! This Lenovo ThinkPad X1 Yoga 2-in-1 laptop is 51% off

How to type an em dash on a Mac

One of HP’s best 2-in-1 laptops just had its price slashed to $460

Weekend deal: Save $350 on this Alienware gaming PC with RTX 4070
Computing News








Laptops








Computing Reviews







Nvidia






Luke Larsen is a Senior Editor at Digital Trends and manages all content covering laptops, monitors, PC hardware, and everything else that plugs into a computer. Luke joined Digital Trends in 2017 as a native Portlander, happy to join a media company that called his city home. His obsession with technology is in observing the ebb and flow of how technological advancement and product design intersects with our day-to-day experience of it. From digging into the minute details to stepping back and seeing the wider trends, Luke revels in telling stories with tech.
Before working at DT, he worked as Tech Editor at Paste Magazine for over four years and has bylines at publications such as IGN and The Oregonian. When he’s not obsessing over what the best laptop is or how Apple can fix the Mac, Luke spends his time playing designer board games, quoting obscure Star Wars lines, and hanging with his family.