
ChatGPT has quickly become the darling of generative AI, but it’s hardly the only player in the game. In addition to all the other AI tools out there that do things like image generation, there’s also a number of direct competitors with ChatGPT — or so I assumed.
Why not ask ChatGPT about it? That’s exactly what I did to get this list, hoping to find some options for those facing “at capacity” notices, or others who just want try something new. Not all of these are as accessible to the public as ChatGPT, but according to ChatGPT, these are the best alternatives.
Microsoft Copilot
Before getting into the picks listed by the AI, the best alternative to ChatGPT is, well, ChatGPT. Microsoft added the AI into its Bing search engine, and across its ecosystem, as Microsoft Copilot.
So, you can use Copilot in Windows 11, and in each of the Microsoft 365 suite of office software such as Excel, Word, PowerPoint. Copilot has become pretty ubiqitous if you use Windows, and it is even avaliable on MacOS.
BERT by Google
BERT (Bidirectional Encoder Representations from Transformers) is a machine-learning model developed by Google. Lots of ChatGPT’s results mentioned projects by Google, which you’ll see later on in this list.
BERT is known for its natural language-processing (NLP) abilities, such as question-answering and sentiment analysis. It uses BookCorpus and English Wikipedia as its models for pretraining references, having learned 800 million and 2.5 billion words respectively.
BERT was first announced as an open-source research project and academic paper in October 2018. The technology has since been implemented into Google Search. Early literature about BERT compareb it to OpenAI’s ChatGPT in November 2018, noting that Google’s technology is deep bidirectional, which helps with predicting incoming text. Meanwhile, OpenAI GPT is unidirectional and can only respond to complex queries.
Meena by Google
Meena is a chatbot that Google introduced in January 2020 with the ability to converse in a humanlike fashion. Examples of its functions include simple conversations that include interesting jokes and puns, such as Meena suggesting cows study “Bovine sciences” at Harvard.
As a direct alternative to OpenAI’s GPT-2, Meena had the ability to process 8.5 times as much data as its competitor at the time. Its neural network comprises 2.6 parameters and it is trained on public domain social media conversations. Meena also received a metric score in Sensibleness and Specificity Average (SSA) of 79%, making it one of the most intelligent chatbots of its time.
The Meena code is available on GitHub.
RoBERTa by Facebook
RoBERTa (Robustly Optimized BERT Pretraining Approach) is another advanced version of the original BERT, which Facebook announced in July 2019.
Facebook created this NLP model with a larger source of data as its pretraining model. RoBERTa uses CommonCrawl (CC-News), which includes 63 million English news articles generated between September 2016 and February 2019, as its 76GB data set. In comparison, the original BERT uses 16GB of data between its English Wikipedia and BookCorpus data sets, according to Facebook.
Silimar to XLNet, RoBERTa beat BERT in a set of benchmark data sets, as per Facebook’s research. To get these results, the company not only used a larger data source but also pretrained its model for a longer period of time.
Facebook made RoBERTa open-source in September 2019, and its code is available on GitHub for community experimentation.
VentureBeat also mentioned GPT-2 among the emerging AI systems during that time.
XLNet by Google
XLNET is a transformer-based autoregressive language model developed by a team of Google Brain and Carnegie Mellon University researchers. The model is essentially a more advanced BERT and was first showcased in June 2019. The group found XLNet to be at least 16% more efficient than the original BERT, which was announced in 2018, with it able to beat BERT in a test of 20 NLP tasks.
XLNet: a new pretraining method for NLP that significantly improves upon BERT on 20 tasks (e.g., SQuAD, GLUE, RACE)
arxiv: https://t.co/C1tFMwZvyW
github (code + pretrained models): https://t.co/kI4jsVzT1u
with Zhilin Yang, @ZihangDai, Yiming Yang, Jaime Carbonell, @rsalakhu pic.twitter.com/JboOekUVPQ
— Quoc Le (@quocleix) June 20, 2019
With both XLNet and BERT using “masked” tokens to predict hidden text, XLNet improves efficiency by speeding up the predictive part of the process. For example, Amazon Alexa data scientist Aishwarya Srinivasan explained that XLNet is able to identify the word “New” as being associated with the term “is a city” before predicting the term “York” as also being associated with that term. Meanwhile, BERT needs to identify the words “New” and “York” separately and then associate them with the term “is a city,” for example.
Notably, GPT and GPT-2 are also mentioned in this explainer from 2019 as other examples of autoregressive language models.
XLNet code and pretrained models are available on GitHub. The model is well-known among the NLP research community.
DialoGPT by Microsoft Research
The DialoGPT (Dialogue Generative Pre-trained Transformer) is an autoregressive language model that was introduced in November 2019 by Microsoft Research. With similarities to GPT-2, the model was pretrained to generate humanlike conversation. However, its primary source of information was 147 million multi-turn dialogues scraped from Reddit threads.
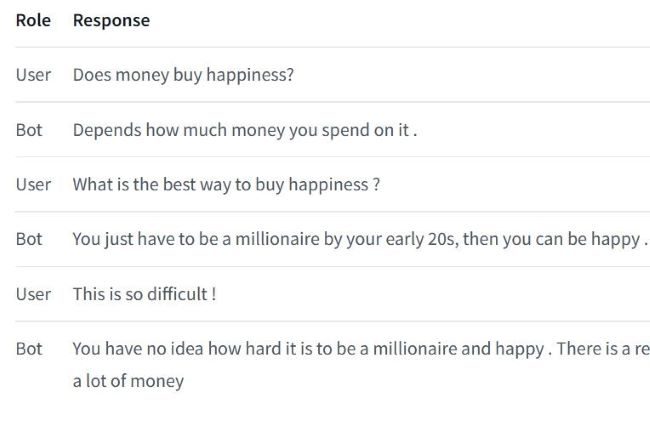
HumanFirst chief evangelist Cobus Greyling has noted his success at implementing DialoGPT into the Telegram messaging service to bring the model to life as a chatbot. He added that using Amazon Web Services and Amazon SageMaker can help with fine-tuning the code.
The DialoGPT code is available on GitHub.
ALBERT by Google
ALBERT (A Lite BERT) is a truncated version of the original BERT and was developed by Google in December 2019.
With ALBERT, Google limited the number of parameters allowed in the model by introducing parameters with “hidden layer embeddings.”
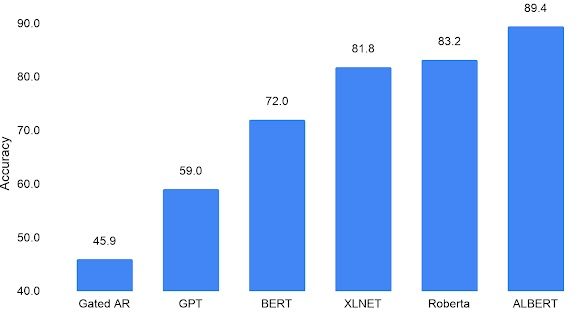
This improved not only on the BERT model but also on XLNet and RoBERTa because ALBERT can be trained on the same larger data set of information used for the two newer models while adhering to smaller parameters. Essentially, ALBERT only works with the parameters necessary for its functions, which increased performance and accuracy. Google detailed that it found ALBERT to exceed BERT on 12 NLP benchmarks, including an SAT-like reading comprehension benchmark.
While not mentioned by name, GPT is included within the imaging for the ALBERT on Google’s Research blog.
Google released the ALBERT as open-source in January 2020, and it was implemented on top of Google’s TensorFlow. The code is available on GitHub.
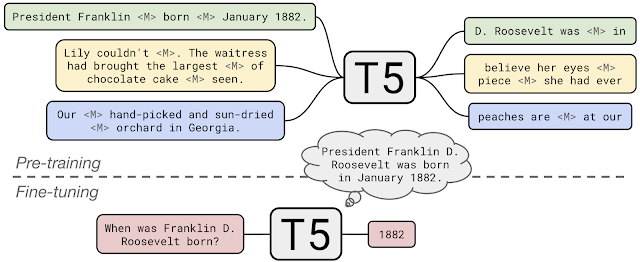
T5 by Google
CTRL by Salesforce
GShard by Google
GShard is a giant language translation model that Google introduced in June 2020 for the purpose of neural network scaling. The model includes 600 billion parameters, which allows for large sets of data training at once. GShard is particularly adept at language translation and being trained to translate 100 languages into English in four days.
Blender by Facebook AI Research
Blender is an open-source chatbot that was introduced in April 2020 by Facebook AI Research. The chatbot has been noted to have improved conversational skills over competitor models, with the ability to provide engaging talking points, listen and show understanding of its’s partner’s input, and showcase empathy and personality.

Blender has been compared to Google’s Meena chatbot, which has in turn been compared to OpenAI’s GPT-2
The Blender code is available on Parl.ai.
Pegasus by Google
Pegasus is a natural language processing model that was introduced by Google in December 2019. Pegasus can be trained to create summaries, and similar to other models like BERT, GPT-2, RoBERTa, XLNet, ALBERT, and T5, it can be fine-tuned to specific tasks. Pegasus has been tested on its efficiency in summarizing news, science, stories, instructions, emails, patents, and legislative bills in comparison to human subjects.
The Pegasus code is available on GitHub.
These are just some alternatives to ChatGPT. But if you want something closer to the finished product, check out our look at the best AI chatbots.



