
It’s back: We’re in the thick of Google’s second wave of its Panda update. And like the first time, it isn’t pretty. The king of search recently reissued the algorithm adjustments for expanded international reach and also included updates as a result of sites users were blocking. “Based on our testing,” the Google web master blog read, “we’ve found the algorithm is very accurate at detecting site quality.” Google also asserted that the second time around would be as severe, affecting about two percent of U.S. queries. Panda originally impacted 12-percent of U.S. searches.
While Google’s algorithm alterations haven’t been as brutal on a large-scale basis, there is no shortage of consequences resulting – and plenty that make just as little sense as the first time around.
Scraper sites persist
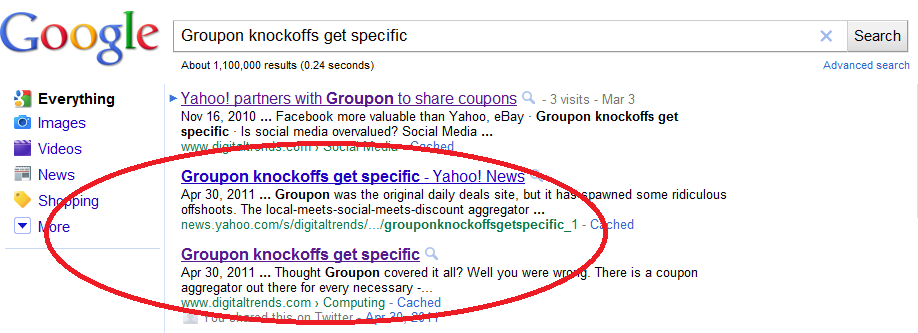
We all know the original purpose for Panda was to crackdown on content farms, which at least makes us feel like Google’s heart was in the right place. While Search Metrics recently reported notorious offender eHow had lost significant traffic (despite its protestations), there are far too many examples of the exact opposite. Regardless of any bias, upon searching “Thor movie review” our own review of the movie, which our writer saw at a press-only screening and published at midnight, is buried somewhere in Google’s no man’s land. However, this pops up on page four:

The RPF is a community and forum “dedicated to props, costumes, and models.” A member of the site posted a link to Gizmodo’s Thor review – the site itself has no such review and also appears in Google’s results before the actual Gizmodo review. HipHopDx also pops up on page four, and the corresponding article is a short write-up and video of Mc Hammer’s thoughts on the film. We also Googled a specific title – and Yahoo, which hosted our article on its own site–popped up ahead of the original article, something we’ve consistently seen not only with our content but many sites’. Using other search engines has not yielded these types of results.
British invasion
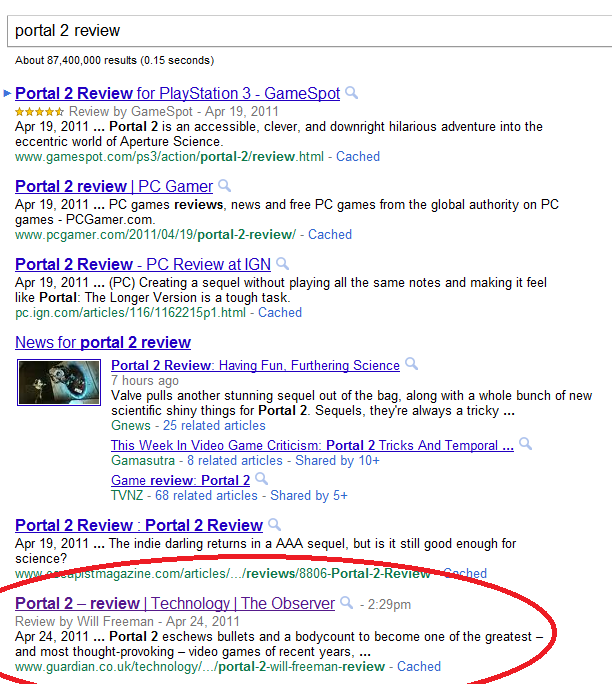
Another anomaly is the amount of U.K. sites getting preference in U.S. searches. British and U.S. video games use different rating systems, so if you want a review of Portal 2, U.K. publication The Guardian is probably not going to be your best source, yet it shows up on page one. We’ve seen this with various video game reviews.
When it comes to world news, there are various excellent, international sources: BBC, The Telegraph, Daily Mail, etc. But in some cases only publications based in your country will lead to the desired information.
The Google standards
Google head of search, Amit Singhal, recently revealed some questions webmasters should ask themselves, and while some of them make sense (i.e. “Would you trust the information presented in this article?”) some seem too objective to serve as universal guidelines (i.e. “Is this the sort of page you’d want to bookmark, share with a friend, or recommend?”).
There’s ample concern that Google’s control over search means that it gets to determine the answers to these questions, many of which can vary widely due to personal opinion. And some sites have questioned the fact that no Google-owned properties have been negatively impacted.
Making the issue even more frustrating is the response – or lack thereof – affected sites are getting. Google is notoriously pro-transparency, until it comes to its search algorithm. Obviously revealing every detail of these practices would result in website-SEO-madness, but various webmasters who have contacted Google asking how they can climb out of the dark hole of search they’ve been banished to have received little to no assistance. Of course there are exceptions, including Overlook, which recently announced Google has finally restored its former rankings.
But paranoia and concern aren’t quite relieved – and they shouldn’t be, considering the amount of control Google has over the world of search.
Editors' Recommendations
- Google may build Gemini AI directly into Chrome
- How to generate AI art right in Google Search
- Apple almost rejected Google for this key Safari feature
- Google’s ChatGPT rival just launched in search. Here’s how to try it
- You don’t have to use Bing – Google Search has AI now, too



