OpenAI is rolling out new functionalities for ChatGPT that will allow prompts to be executed with images and voice directives in addition to text.
The AI brand announced on Monday that it will be making these new features available over the next two weeks to ChatGPT Plus and Enterprise users. The voice feature is available in iOS and Android in an opt-in capacity, while the images feature is available on all ChatGPT platforms. OpenAI notes it plans to expand the availability of the images and voice features beyond paid users after the staggered rollout.
The voice chat functions as an auditory conversation between the user and ChatGPT. You press the button and say your question. After processing the information, the chatbot gives you an answer in auditory speech instead of in text. The process is similar to using virtual assistants such as Alexa or Google Assistant and could be the preamble to a complete revamp of virtual assistants as a whole. OpenAI’s announcement comes just days after Amazon revealed a similar feature coming to Alexa.
To implement voice and audio communication with ChatGPT, OpenAI uses a new text-to-speech model that is able to generate “human-like audio from just text and a few seconds of sample speech.” Additionally, its Whisper model can “transcribe your spoken words into text.”
OpenAI says it’s aware of the issues that could arise due to the power behind this feature, including, “the potential for malicious actors to impersonate public figures or commit fraud.”
This is one of the main reasons the company plans to limit the use of its new features to “specific use cases and partnerships.” Even when the features are more widely available they will be accessible mainly to more privileged users, such as developers.
ChatGPT can now see, hear, and speak. Rolling out over next two weeks, Plus users will be able to have voice conversations with ChatGPT (iOS & Android) and to include images in conversations (all platforms). https://t.co/uNZjgbR5Bm pic.twitter.com/paG0hMshXb
— OpenAI (@OpenAI) September 25, 2023
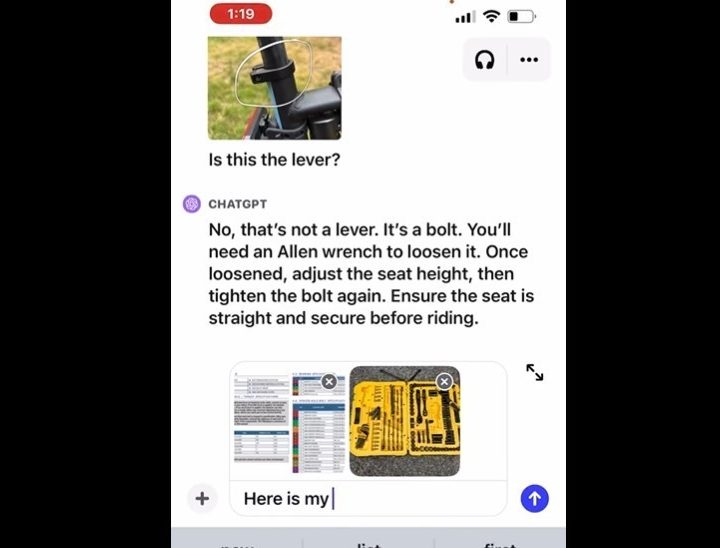
The image feature allows you to capture an image and input it into ChatGPT with your question or prompt. You can use the drawing tool with the app to help clarify your answer and have a back-and-forth conversation with the chatbot until your issue is resolved. This is similar to Microsoft’s new Copilot feature in Windows, which is built on OpenAI’s model.
OpenAI has also acknowledged the challenges of ChatGPT, such as its ongoing hallucination issue. When aligned with the image feature, the brand decided to limit certain functionalities, such as the chatbot’s “ability to analyze and make direct statements about people.”
ChatGPT was first introduced as a text-to-speech tool late last year; however, OpenAI has quickly expanded its prowess. The original chatbot based on the GPT-3 language model has since been updated to GPT-3.5 and now GPT-4, which is the model that is receiving the new feature.
When GPT-4 first launched in March, OpenAI announced various enterprise collaborations, such as Duolingo, which used the AI model to improve the accuracy of the listening and speech-based lessons on the language learning app. OpenAI has collaborated with Spotify to translate podcasts into other languages while preserving the sound of the podcaster’s voice. The company also spoke of its work with the mobile app, Be My Eyes, which works to aid blind and low-vision people. Many of these apps and services were available ahead of the images and voice update.