
Artificial general intelligence, the idea of an intelligent A.I. agent that’s able to understand and learn any intellectual task that humans can do, has long been a component of science fiction. As A.I. gets smarter and smarter — especially with breakthroughs in machine learning tools that are able to rewrite their code to learn from new experiences — it’s increasingly widely a part of real artificial intelligence conversations as well.
But how do we measure AGI when it does arrive? Over the years, researchers have laid out a number of possibilities. The most famous remains the Turing Test, in which a human judge interacts, sight unseen, with both humans and a machine, and must try and guess which is which. Two others, Ben Goertzel’s Robot College Student Test and Nils J. Nilsson’s Employment Test, seek to practically test an A.I.’s abilities by seeing whether it could earn a college degree or carry out workplace jobs. Another, which I should personally love to discount, posits that intelligence may be measured by the successful ability to assemble Ikea-style flatpack furniture without problems.
One of the most interesting AGI measures was put forward by Apple co-founder Steve Wozniak. Woz, as he is known to friends and admirers, suggests the Coffee Test. A general intelligence, he said, would mean a robot that is able to go into any house in the world, locate the kitchen, brew up a fresh cup of coffee, and then pour it into a mug.
As with every A.I. intelligence test, you can argue about how broad or narrow the parameters are. However, the idea that intelligence should be linked to an ability to navigate through the real world is intriguing. It’s also one that a new research project seeks to test out.
Building worlds
“In the last few years, the A.I. community has made huge strides in training A.I. agents to do complex tasks,” Luca Weihs, a research scientist at the Allen Institute for AI, an artificial intelligence lab founded by the late Microsoft co-founder Paul Allen, told Digital Trends.

Weihs cited DeepMind’s development of A.I. agents that are able to learn to play classic Atari games and beat human players at Go. However, Weihs noted that these tasks are “frequently detached” from our world. Show a picture of the real world to an A.I. trained to play Atari games, and it will have no idea what it is looking at. It’s here that the Allen Institute researchers believe they have something to offer.
The Allen Institute for A.I. has built up something of a real estate empire. But this isn’t physical real estate, so much as it is virtual real estate. It’s developed hundreds of virtual rooms and apartments — including kitchens, bedrooms, bathrooms, and living rooms — in which A.I. agents can interact with thousands of objects. These spaces boast realistic physics, support for multiple agents, and even states like hot and cold. By letting A.I. agents play in these environments, the idea is that they can build up a more realistic perception of the world.
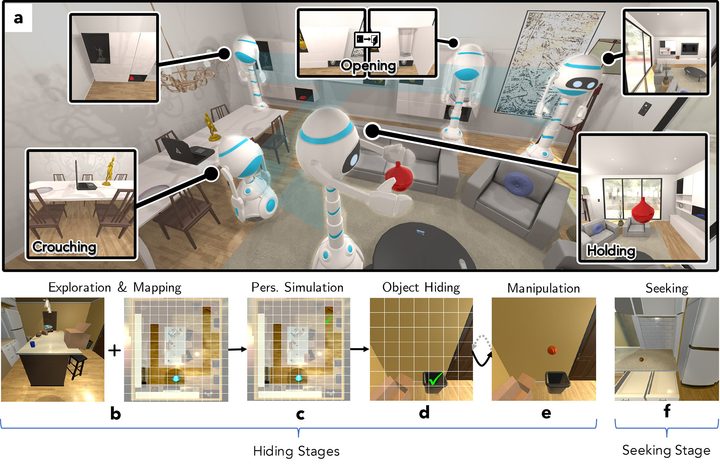
“In [our new] work, we wanted to understand how A.I. agents could learn about a realistic environment by playing an interactive game within it,” Weihs said. “To answer this question, we trained two agents to play Cache, a variant of hide-and-seek, using adversarial reinforcement learning within the high-fidelity AI2-THOR environment. Through this gameplay, we found that our agents learned to represent individual images, approaching the performance of methods requiring millions of hand-labeled images — and even began to develop some cognitive primitives often studied by [developmental] psychologists.”
Rules of the game
Unlike regular hide-and-seek, in Cache, the bots take turns hiding objects such as toilet plungers, loaves of bread, tomatoes, and more, each of which boast their own individual geometries. The two agents — one a hider, the other a seeker — then compete to see if one can successfully hide the object from the other. This involves a number of challenges, including exploration and mapping, understanding perspective, hiding, object manipulation, and seeking. Everything is accurately simulated, even down to the requirement that the hider should be able to manipulate the object in its hand and not drop it.
Using deep reinforcement learning — a machine learning paradigm based on learning to take actions in an environment to maximize reward — the bots get better and better at hiding the objects, as well as seeking them out.
“What makes this so difficult for A.I.s is that they don’t see the world the way we do,” Weihs said. “Billions of years of evolution has made it so that, even as infants, our brains efficiently translate photons into concepts. On the other hand, an A.I. starts from scratch and sees its world as a huge grid of numbers which it then must learn to decode into meaning. Moreover, unlike in chess, where the world is neatly contained in 64 squares, every image seen by the agent only captures a small slice of the environment, and so it must integrate its observations through time to form a coherent understanding of the world.”
To be clear, this latest work isn’t about building a supe-intelligent A.I. In movies like Terminator 2: Judgment Day, the Skynet supercomputer achieves self-awareness at precisely 2.14 a.m. Eastern Time on August 29, 1997. Notwithstanding the date, now almost a quarter century in our collective rearview mirror, it seems unlikely that there will be such a precise tipping point when regular A.I. becomes AGI. Instead, more and more computational fruits — low-hanging and high-hanging — will be plucked until we finally have something approaching a generalized intelligence across multiple domains.
Hard stuff is easy, easy stuff is hard
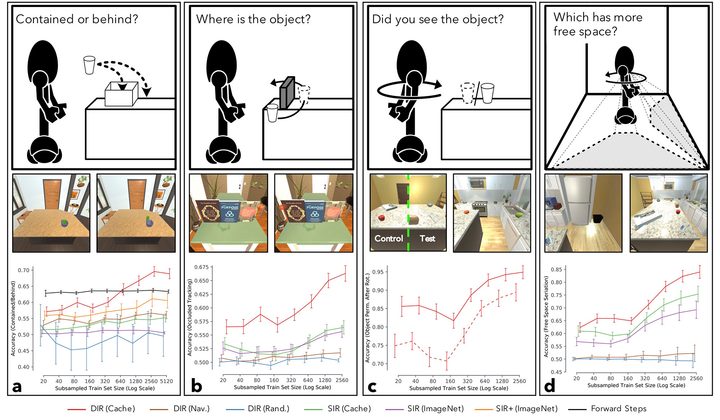
Researchers have traditionally gravitated toward complex problems for A.I. to solve based on the idea that, if the tough problems can be sorted, the easy ones shouldn’t be too far behind. If you can simulate the decision-making of an adult, can ideas like object permanence (the idea that objects still exist when we can’t see them) that a child learns within the first few months of its life really prove that difficult? The answer is yes — and this paradox that, when it comes to A.I., the hard stuff is frequently easy, and the easy stuff is hard, is what work such as this sets out to address.
“The most common paradigm for training A.I. agents [involves] huge, manually labeled datasets narrowly focused to a single task — for instance, recognizing objects,” said Weihs. “While this approach has had great success, I think it is optimistic to believe that we can manually create enough datasets to produce an A.I. agent that can act intelligently in the real world, communicate with humans, and solve all sorts of problems that it hasn’t encountered before. To do this, I believe we will need to let agents learn the fundamental cognitive primitives we take for granted by letting them freely interact with their world. Our work shows that using gameplay to motivate A.I. agents to interact with and explore their world results in them beginning to learn these primitives — and thereby shows that gameplay is a promising direction away from manually abeled datasets and towards experiential learning.”
A paper describing this work will be presented at the upcoming 2021 International Conference on Learning Representations.



