Even if you aren’t on Twitter, simply using the Internet (or watching TV) means you probably know about Twitter and its famous 140-character messages. Whether you consider it a fad, a social network, or a tool for photo or video sharing, Twitter is almost certainly in your face.
Twitter passed the 500-million-user milestone last year, meaning as many as one in eight people worldwide are on board. In theory, Twitter is a way to peer into the collective consciousness of the Internet — almost in real time. But the everyday Twitter experience remains surprisingly narrow: Most of us follow friends and family, a news source or two, and perhaps some celebrities or brands. But what about the big picture being painted by those hundreds of millions of users? What can we glean from our collective tweeting?
How tweet it is

Twitter itself doesn’t reveal much about its users or its own overall activity. Aside from self-congratulatory blog posts about events like the Super Bowl, Twitter merely highlights current hashtags and topics in its site and apps, and forgets them within minutes or hours. Unless your world revolves around something like #ExplainToMeWhy or boasting about follower counts, it’s not a deep look at Twitter’s overall spirit.
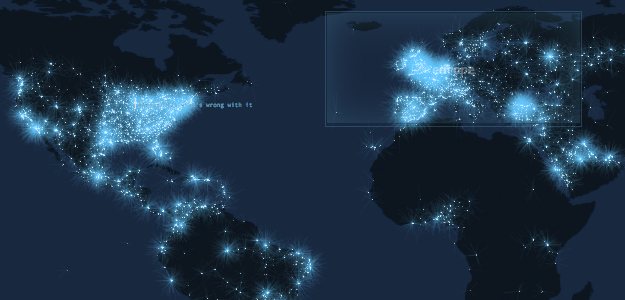
However, access to near real-time Twitter data has inspired efforts to look for patterns in tweet activity. An early example was Nikhil Bobb‘s A View from Above. It’s more of an aesthetic experiment than a utility, but it plots tweets with location data as flares on a black background: the more tweets in an area, the bigger and brighter the flare.
“The early inspiration was to approximate how an omnipotent being would see humanity from above,” Bobb wrote via email. “As I got more into the project, I found the digital cityscapes were a different and often more beautiful reflection of their geographic equivalents.”
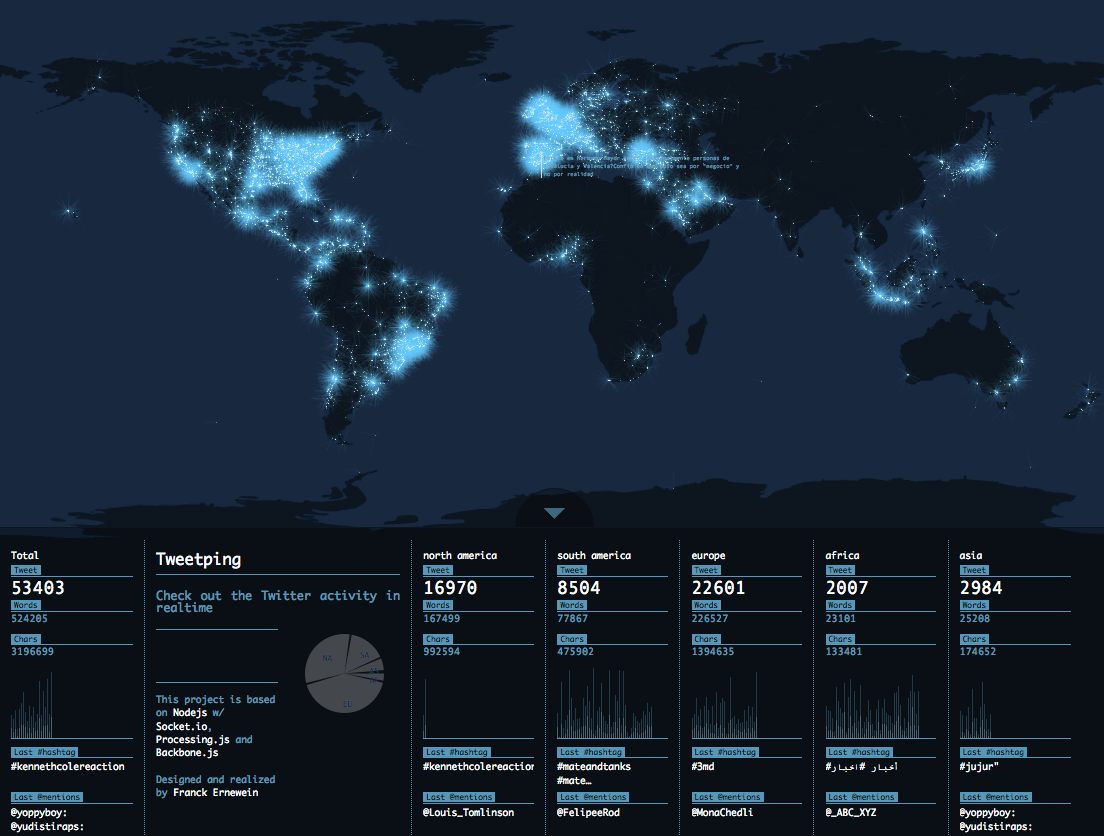
Franck Ernewein’s TweetPing takes that idea one step further, plotting global tweets in real time against a map of the world. It’s an intriguing display — particularly when one realizes how few tweets seem to originate in Africa, let alone Iran or China. But watching TweetPing also reveals shortcomings. At almost any hour, hotspots like the U.S. east coast, western Europe, Tokyo, Indonesia, and Brazil’s southeast coast become incandescent, yet India remains almost dark. No one tweets in India? One might see more tweets from Greenland or Antarctica than Morocco, Bangladesh, or Madagascar. Sure, China blocks Twitter outright, but the real issue is that tweets don’t include GPS info. Last year, Semiocast estimated fewer than one percent of tweets included location data. The fascinating visuals of TweetPing (and A View From Above) reflect just a handful of Twitter users comfortable with (or capable of) sharing their location.
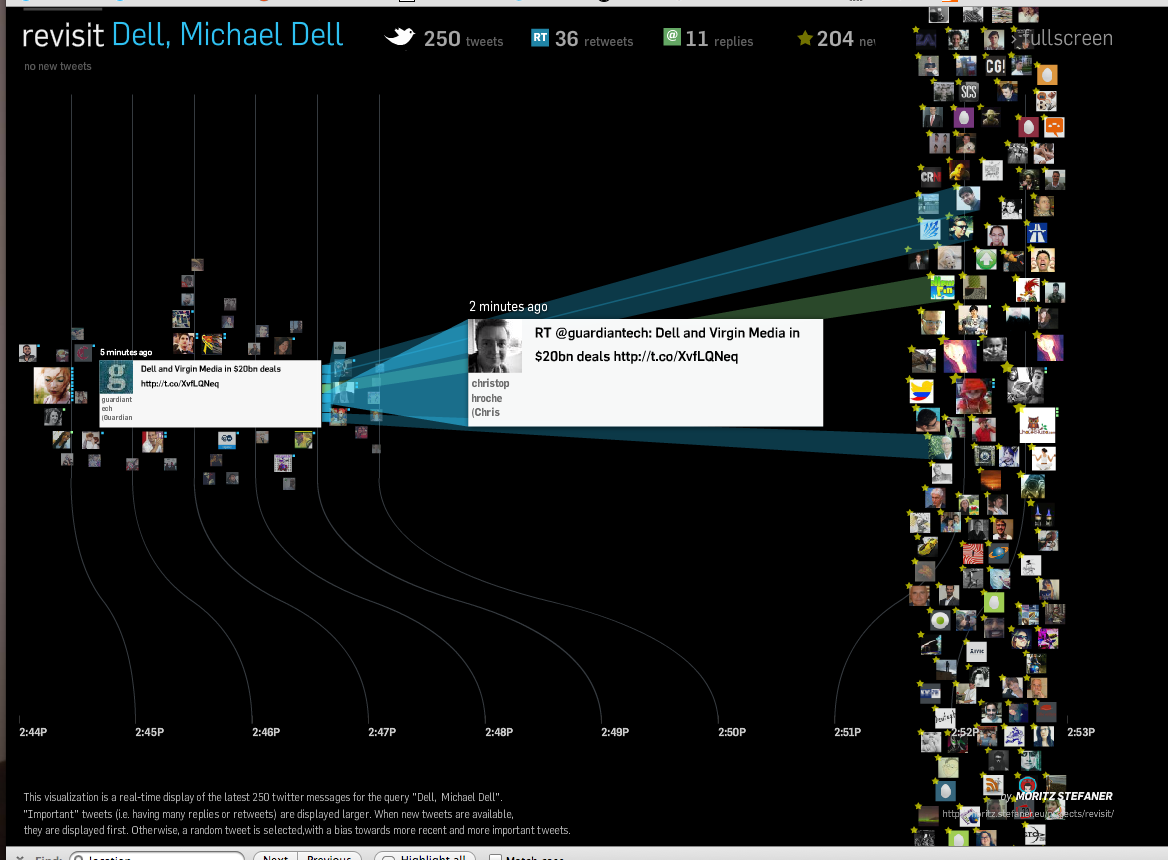
If a bird’s-eye view of Twitter clearly has limits, what about a topical view? Freelance information visualizer Moritz Stefaner took that on with Revisit, a Flash-based timeline that displays recent tweets matching search terms (like “iPhone” or “Seattle”). Revisit emphasizes conversations, highlighting replies and retweets. Where TweetPing offers a global view, Revisit is almost microscopic, intended for specific topics or events — but watching the ebb and flow can be just as fascinating.
Why Twitter’s hard to handle

These projects are just examples, but they demonstrate why Twitter is a tough problem: there’s just so much data. A comprehensive “Twitter tracker” might be impossible. Heck, Twitter itself hasn’t built one.
The highest-profile effort may be at the Library of Congress, which is creating a complete archive of every tweet going back to 2006. (Right now, it’s on tape, according to a recent white paper.) It’s ambitious: the Library of Congress started work in 2010, and is only now moving towards granting researchers access — public access is a long way off.
Why is it taking so long? If search engines like Google and Bing offer real-time Internet search, what’s hard about making Twitter searchable? It’s all about volume. Jamie de Guerre of the analytics firm Topsy recently noted Internet search engines might index 125 billion Web pages. In comparison, the Library of Congress’s Twitter archive is already over 170 billion tweets. That’s an apples-and-oranges comparison, but, in some ways, Twitter is a bigger problem than Internet search.
“Search engine companies have invested a lot of human and financial resources in building entire businesses on search. As a public institution, it is not practical for the Library to replicate that kind of investment,” wrote Gayle Osterberg, Director of Communications for the Library of Congress.
The private sector might help out with public access, but the details could be complicated: Think about advertising or charging for access. Still, there’s hope:
“We are looking at public-private partnerships to achieve some level of access,” noted Osterberg.
Tweet and consequences
Just as TweetPing uses the small number of tweets with location data, Twitter itself is not level ground. A 2011 study found U.S. Twitter users were disproportionately Caucasian, male, and urban. These demographics complicate any conclusions drawn from its data.
Nonetheless, the potential of the content and interaction tucked away in Twitter is staggering.
“Twitter provides us with an unprecedented, direct access to people’s ideas and thoughts at any given point in time,” noted Revisit creator Mortiz Stefaner. “I think we have only scratched the tip of the iceberg in what can be extracted.”
Meanwhile, the best and most accurate view of Twitter remains close to home in our own timelines — and it may be a long time before anyone else can make sense of us.


