
Deep learning is a particular subset of machine learning (the mechanics of artificial intelligence). While this branch of programming can become very complex, it started with a very simple question: “If we want a computer system to act intelligently, why don’t we model it after the human brain?”
That one thought spawned many efforts in past decades to create algorithms that mimicked the way the human brain worked—and that could solve problems the way that humans did. Those efforts have yielded valuable, increasingly competent analysis tools that are used in many different fields.
The neural network and how it’s used
Deep learning gets its name from how it’s used to analyze “unstructured” data, or data that hasn’t been previously labeled by another source and may need definition. That requires careful analysis of what the data is, and repeated tests of that data to end up with a final, usable conclusion. Computers are not traditionally good at analyzing unstructured data like this.
Think about it in terms of writing: If you had ten people write the same word, that word would look very different from each person, from sloppy to neat, and from cursive to print. The human brain has no problem understanding that it’s all the same word, because it knows how words, writing, paper, ink, and personal quirks all work. A normal computer system, however, would have no way of knowing that those words are the same, because they all look so different.
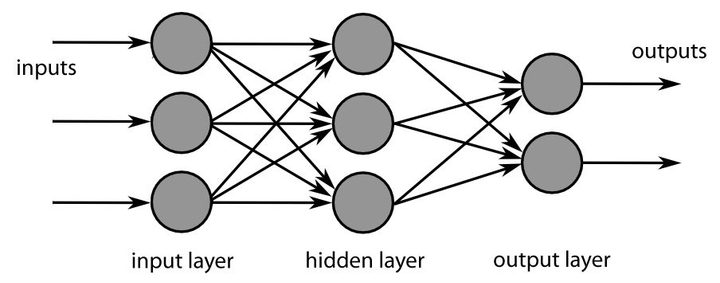
That brings us to via neural networks, the algorithms specifically created to mimic the way that the neurons in the brain interact. Neural networks attempt to parse data the way that a mind can: Their goal is to deal with messy data—like writing—and draw useful conclusions, like the words that writing is attempting to show. It’s easiest to understand neural networks if we break them into three important parts:
The input layer: At the input layer, the neural network absorbs all the unclassified data that it is given. This means breaking down the information into numbers and turning them into bits of yes-or-no data, or “neurons”. If you wanted to teach a neural network to recognize words, then the input layer would be mathematically defining the shape of each letter, breaking it down into digital language so the network can start working. The input layer can be pretty simple or incredibly complex, depending on how easy it is to represent something mathematically.
The hidden layers: At the center of the neural network are hidden layers—anywhere from one to many. These layers are made of their own digital neurons, which are designed to activate or not activate based on the layer of neurons that precedes them. A single neuron is a basic “if this, then that“ model, but layers are made of long chains of neurons, and many different layers can influence each other, creating very complex results. The goal is to allow the neural network to recognize many different features and combine them into a single realization, like a child learning to recognize each letter and then forming them together to recognize a full word, even if that word is written a little sloppy.
The hidden layers are also where a lot of deep learning training goes on. For example, if the algorithm failed to accurately recognize a word, programmers send back, “Sorry, that’s not correct,” and the algorithm would adjust how it weighed data until it found the right answers. Repeating this process (programmers may also adjust weights manually) allows the neural network to build up robust hidden layers that are adept at seeking out the right answers through a lot of trial and error plus, some outside instruction — again, much like how the human brain works. As the above image shows, hidden layers can become very complex!
The output layer: The output layer has relatively few “neurons” because it’s where the final decisions are made. Here the neural network applies the final analysis, settles on definitions for the data, and draws the programmed conclusions based on those definitions. For example, “Enough of the data lines up to say that this word is lake, not lane.” Ultimately all data that passes through the network is narrowed down to specific neurons in the output layer. Since this is where the goals are realized, it’s often one of the first parts of the network created.
Applications

If you use modern technology, chances are good that deep learning algorithms are at work all around you, every day. How do you think Alexa or Google Assistant understand your voice commands? They use neural networks that have been built to understand speech. How does Google know what you’re searching for before you’re done typing? More deep learning at work. How does your security cam ignore pets but recognize human movement? Deeping learning once again.
Anytime that software recognizes human inputs, from facial recognition to voice assistants, deep learning is probably at work somewhere underneath. However, the field also has many other useful applications. Medicine is a particularly promising field, where advanced deep learning is used to analyze DNA for flaws or molecular compounds for potential health benefits. On a more physical front, deep learning is used in a growing number of machines and vehicles to predict when equipment needs maintenance before something goes seriously wrong.
The future of deep learning

The future of deep learning is particularly bright! The great thing about a neural network is that it excels at dealing with a vast amount of disparate data (think of everything our brains have to deal with, all the time). That’s especially relevant in our era of advanced smart sensors, which can gather an incredible amount of information. Traditional computer solutions are beginning to struggle with sorting, labeling and drawing conclusions from so much data.
Deep learning, on the other hand, can deal with the digital mountains of data we are gathering. In fact, the larger the amount of data, the more efficient deep learning becomes compared to other methods of analysis. This is why organizations like Google invest so much in deep learning algorithms, and why they are likely to become more common in the future.
And, of course, the robots. Let’s never forget about the robots.



