

Twitter’s API is getting two important additions to its metadata, the company announced via blog post. Developers can now detect a tweet’s language, as well as algorithmic curation to surface “high value” tweets.
First off, to detect the language of a tweet, the updated API uses Twitter’s machine language detection algorithm, which should help developers better serve its users (especially to an international crowd) with language specific aggregation, analysis, and curation of tweets. For instance, developers can manually pick out the types of languages that they’d like to have surface in their app while burying tweets from unspecified languages. In one scenario, the parameter “language=ja” would display only tweets in the Japanese language. If you’re wondering where the “ja” abbreviation comes from, Twitter uses the two-letter ISO 639-1 code, which corresponds to certain languages.
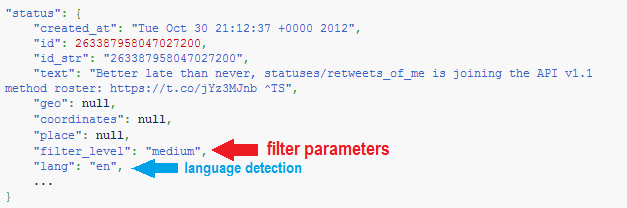
Twitter’s second update will offer developers the option to choose from “none,” “low,” “medium,” and “high” values, meaning that developer can tell Twitter how much they’d like to filter streaming tweets. This part of the API would be used to separate the important tweets from the noise in high-volume feeds, per Twitter’s own algorithm which sorts “high value” tweets from the rest. To get a better sense of what the values mean, Twitter’s “Developer Advocate,” Arne Roomann-Kurrik, writes that the medium entries, “roughly correlate to the ‘Top Tweets’ results for searches on twitter.com.”
This piece of info clues us into what’s actually powering the streams. Early last month, Twitter revealed that its real-time search engine was partially human powered (via Amazon’s Mechanical Turk) to better add context to tweets. The human element, for now, is the best and fastest way to add context to topics like “binders full of women,” which may suddenly have a new meaning overnight.
To get a better sense of how Twitter’s human search engine plays into this updated API, we’ll have to get technical for a moment. Developers can set one of the four values mentioned above, which in the code would sit next to the “filter_level” parameter. If “filter_level”: “none” then this defines no filtering. “Medium” on the other hand offers the most filtering, and if a developer has chosen the “medium” parameter, all “Top Tweets” that Twitter spits out into the developer’s client are search results that have been influenced by Twitter’s human real-time search engine.
For now, it looks like a “high” value doesn’t yet correspond to any amount of filtering. But say that “medium” does correspond to the human powered search results, which Roomann-Kurrik seems to suggest. That would mean that Twitter for now is setting aside a type of filter that would be far more powerful than “medium.” So any development here is worth keeping an eye on.
The “value” based filters will be launching on February 20, and the language filter will follow shortly thereafter, although a hard date hasn’t yet been set for that.



