

The internet has a hate speech problem.
Go to any YouTube comments section or trawl social media for even a short amount of time and you’ll find no shortage of offensive, frequently prejudiced comments. But how do you solve this problem? And, in doing so, how do you avoid accidentally making it worse?
This month, two hate speech-seeking A.I. algorithms were announced: One created in the United Kingdom, the other in the U.S. Both could one day be used to scour social media or other areas of the online world, and highlight hate speech or offensive speech so that it can be reported, deleted, or blocked.
The first, developed by researchers from the U.K.’s University of Exeter, is a tool named Lola that harnesses the “latest advances in natural language processing and behavioral theory” to scan through thousands of messages a minute to uncover hateful content. “The level of accuracy is outstanding compared to existing solutions in the market,” Dr. David Lopez, one of Lola’s creators, told Digital Trends.
The second, the work of researchers at the University of Southern California, claims to be capable of something similar. “The algorithm we developed is a text classifier, which takes social media posts — or potentially other text — and predicts whether the text contains hate speech or not,” Brendan Kennedy, a computer science Ph.D. student who worked on the project, told Digital Trends.
This is a job for automation. Kind of
To appreciate why it’s necessary to turn to automated solutions to solve this most human of problems, it’s crucial to understand the sheer scale of social media. Each second of the day, an average of 6,000 tweets are sent. This equates to 350,000 tweets a minute, 500 million tweets a day or 200 billion tweets a year. On Facebook, approximately 35 million people update their statuses on a daily basis.
Even for well-staffed tech giants, those numbers make it infeasible for human moderators to do the necessary moderation on their own. Such decisions must be made very quickly, not just to stay on top of the new content generated every moment, but also so that certain messages are not seen by large numbers of users. Well-designed algorithms are the only practical way of solving this problem.
“Each second of the day, an average of 6,000 tweets are sent. This equates to 350,000 tweets a minute, 500 million tweets a day or 200 billion tweets a year”
Using machine learning, it is possible — at least in theory — to develop tools that can be trained to seek out hate speech or offensive speech so that it can be deleted or reported. But this isn’t easy. Hate speech is a broad and contested term. Attempts to define it legally or even informally among humans proves difficult. Some examples of hate speech might be so clear-cut that no one can dispute them. But other cases may be more subtle; the type of actions more likely to be classed as “micro-aggressions.” As United States Supreme Court Justice Potter Stewart famously said about obscenity: “I know it when I see it.”
“There are many types of hate speech [and] offensive language,” Kennedy told Digital Trends. “Some hate speech is easy to flag — for example, slurs. But most hate speech is rhetorically complex, demonizing and dehumanizing through metaphor, culturally-specific stereotypes, and ‘dog-whistles.’”
Making the problem worse, not better
Previous hate speech-hunting A.I. tools have proven ineffective because they are too blunt an instrument to uncover more complex examples of prejudice online. Poorly designed hate speech detection algorithms, far from stopping hateful speech online, have actually been shown to amplify things like racial bias by blocking non-offensive tweets sent by minority groups. That could be something as simple as the fact that hate speech classifiers are oversensitive to terms like “Black”, “gay” or “transgender” which may be more likely to be associated with hateful content in some settings.
Just like Microsoft’s infamous Tay chatbot, which learned racist behavior after interacting with users, classifiers that are trained on original social media text data can wind up leaning heavily on specific words while ignoring or being unaware of their surrounding context.
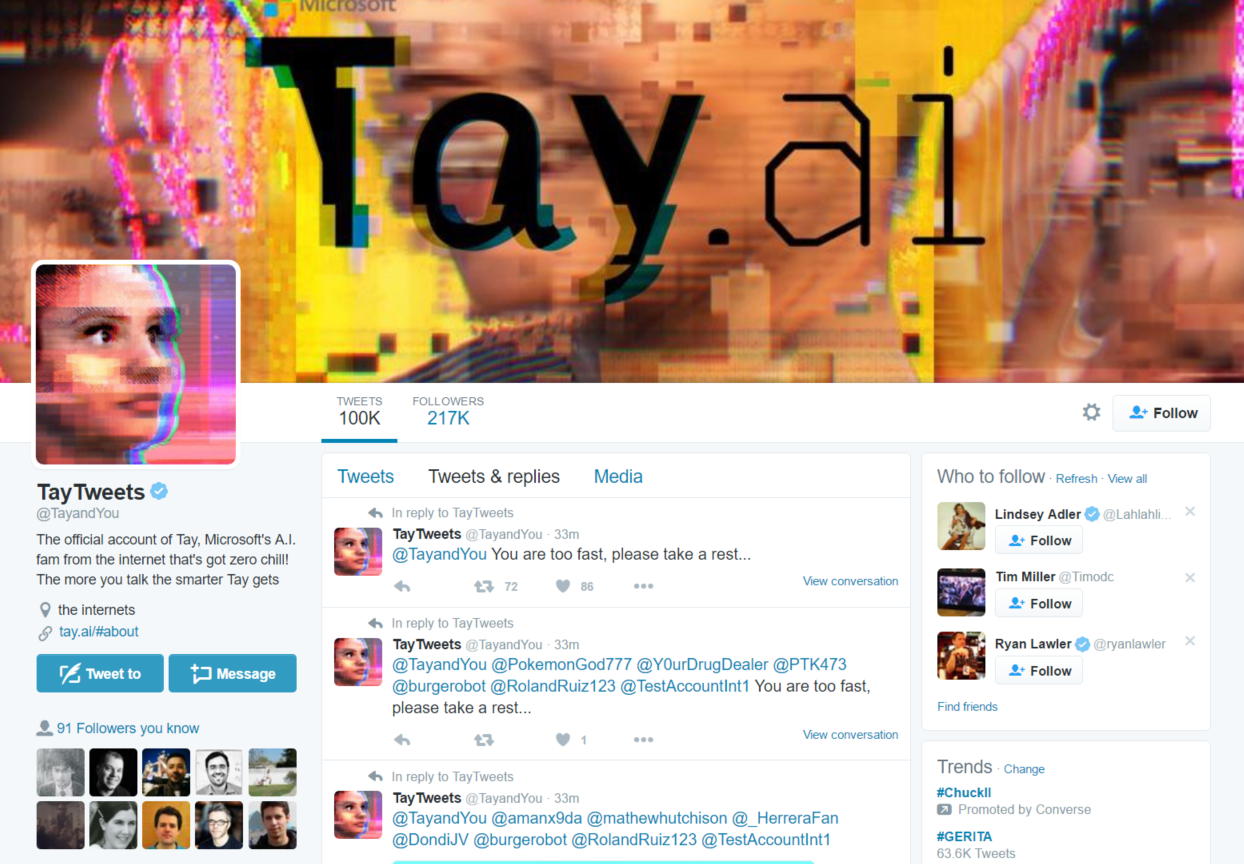 s
s
The ability to better analyze online messages in context is what the two new A.I. detection systems promise. The U.K.’s Lola system claims to be able to analyze 25,000 messages per minute to detect harmful behaviors — including cyberbullying, hatred, and Islamophobia — with up to 98% accuracy. Part of this is looking not just at keywords, but by using an “emotion detection engine” to work out what emotions are elicited in the text — whether this be love, anger, fear, trust, or others.
Meanwhile, the University of Southern California A.I. detection system promises to look at the context as well as the content.
“Our starting point in this research is a standard method, which encodes sequences of text tokens into numeric vectors, which are [then] used to probabilistically output the class label of ‘hate’ or ‘no hate,’” Brandon said. “Using a ‘post-hoc explanation’ algorithm that members of our team developed, we programmed hate speech classifiers to give less importance to group identifiers, and more importance to the context surrounding group identifiers.”
The system was tested by analyzing articles from white supremacist website Stormfront and the more neutral reportage of the New York Times. Its creators claim it was capable of sorting hate from non-hate content with an accuracy level of 90%.
A war on two fronts
It’s not only independent researchers who are developing tools for detecting hate speech, however. Social networks are also working to solve this problem.
“We now remove 10 million pieces of hate speech a quarter,” Amit Bhattacharyya, director of product management in Facebook’s community integrity group, told Digital Trends. “Of that, about 90% was detected before users reported it to us. We have invested more in — and gotten better at — proactively detecting potentially violating content, including hate speech.”
Facebook’s detection techniques, Bhattacharyya explained, focus on things like text and image matching, in which it looks for images and identical strings of text that have already been removed as hate speech elsewhere on the platform. It also uses machine learning classifiers that analyze language and other content types. Facebook has additional data points, too, since it can look at the reactions and comments to a post to see how closely these match common phrases, patterns, and attacks seen previously in content that violates its hate speech policies.
“Cracking down on abusive behavior online does not have to be reactive. It can be proactive, too.”
Twitter also uses machine learning tools to crack down on hateful content. Some of this is keyword-based, but Twitter additionally analyzes user behavior to try and determine how comfortable users are in interactions. For instance, a user who tweets at another user and is replied to and then followed will be viewed differently to one who tweets directly to another person repeatedly but is ignored or blocked. These behavioral dynamics can help reveal patterns of harassment or unwanted targeted behavior that Twitter can then use to better understand the content of what is going on on its platform.
However, a Twitter spokesperson told Digital Trends that messages flagged as offensive are manually reviewed by humans (in a machine-prioritized order) so as to determine that they have been correctly identified as such.
An ongoing challenge
Facebook’s Bhattacharyya said that the social network has made “great progress” over the years in curbing hate speech on its platforms and that its team is proud of what it has accomplished. At the same time, Bhattacharyya said, “Our work is never complete and we know that we may never be able to prevent every piece of hateful content from appearing on our platforms.”
The depressing reality is that online hate speech will probably never be solved as a problem. At least, not without people making a change. The internet might, to its detriment, amplify certain human voices, and embed and codify particular human prejudices, but that’s because it’s just humanity writ large. Whatever problems exist in the real world will, to an extent, make their way into the online world.

That said, cracking down on abusive behavior online does not have to be reactive. It can be proactive, too. For instance, the Twitter spokesperson who talked with Digital Trends pointed out that, of the users who have accounts banned for 12 hours due to rule infractions, the majority do offend again. This suggests that teachable moments can occur. Whether they genuinely prompt users to reexamine their behavior or simply stop them behaving in a way that breaks the rules, it nonetheless reduces upsetting rule-breaking behavior on the platform.
The spokesperson also said that Twitter is now exploring a “nudge”-based system. This will offer prompts before users tweet, alerting them that what they are about to post could run afoul of Twitter’s rules. This might be because of a particular keyword. When sharing an article you have not opened via Twitter, it might also offer a warning. This nudge system was recently tested with a small number of users. While the trial has now concluded, there is a possibility it could be rolled out as a feature to all users in the future.
The future of discourse on the internet
The question of hate speech and other offensive speech on social media is only to become more pressing. In France, for example, a law was passed in May that calls for certain criminal content to be removed from social media within an hour. If it isn’t, the social media companies in question will face a fine of up to 4% of their global revenue. Other “manifestly illicit” content must be removed within 24 hours. Justice Minister Nicole Belloubet told the French Parliament that the law would help to reduce online hate speech.
No such law has, as far as we’re aware, been seriously proposed in the United States. But as social media becomes an ever-larger and more influential part of how we communicate, cracking down on toxic behavior will become increasingly important. This is not a problem that can be addressed purely by human moderators. But it’s also one that, when it is undertaken using A.I., must be done carefully — not just to ensure that it makes the problem better, but to guarantee that it doesn’t make it worse.
The future of discourse on the internet depends on it.



