- Home
- Computing
Computing
Computing is the foundation on which the rest of technology is built, but it’s also the lens through which we see the future. That’s why we take it seriously at Digital Trends. Our approach includes coverage of the hardware and software of PCs, but also the larger ecosystem of everything that plugs into them. Windows, Macs, laptops, graphics cards, CPUs, gaming monitors, and yes — even printers. And that’s just scratching the surface.
Through covering the latest news and performing the hands-on testing ourselves, we’re able to offer the best PC buying advice you’ll find on the internet. We do our own in-depth testing on everything from the battery life of laptops to monitor image quality. We even delve into the expanding world of the PC gaming tech with ReSpec, our biweekly deep-dive column on making your PC games look and play their best.
So, whether you’re shopping for your next laptop, reading up on the latest GPU news for your next upgrade, or just trying to take a screenshot on Mac, you’ve come to the right place.
Explore More

A new technology teaching drones to feel pain could stop your self-driving car from harming itself







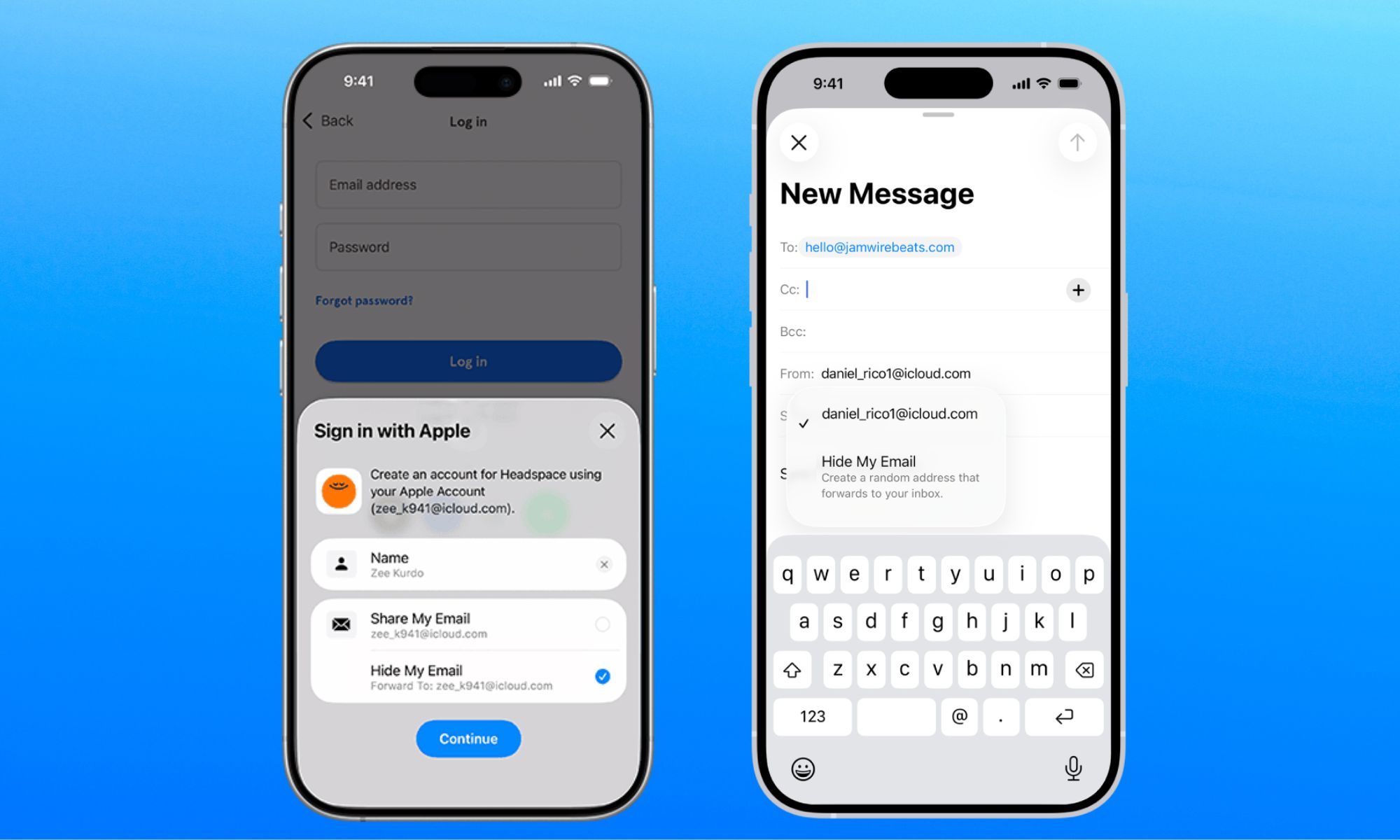
Apple’s Hide My Email feature has an unfixed bug that leaves email addresses exposed

I hate sharing my Mac, but a face-unlocking app finally cured my privacy paranoia

The charm of a tiny Windows tablet is apparently dead at Microsoft. Long live the Surface Go!

Gemini Spark lands on the Mac, and it wants to tackle your chores while you relax

Anthropic finally brings back Claude Fable 5, but you’ll have to live with a temporary usage limit

Claude’s Sonnet 5 is built to do more on its own and cost you less
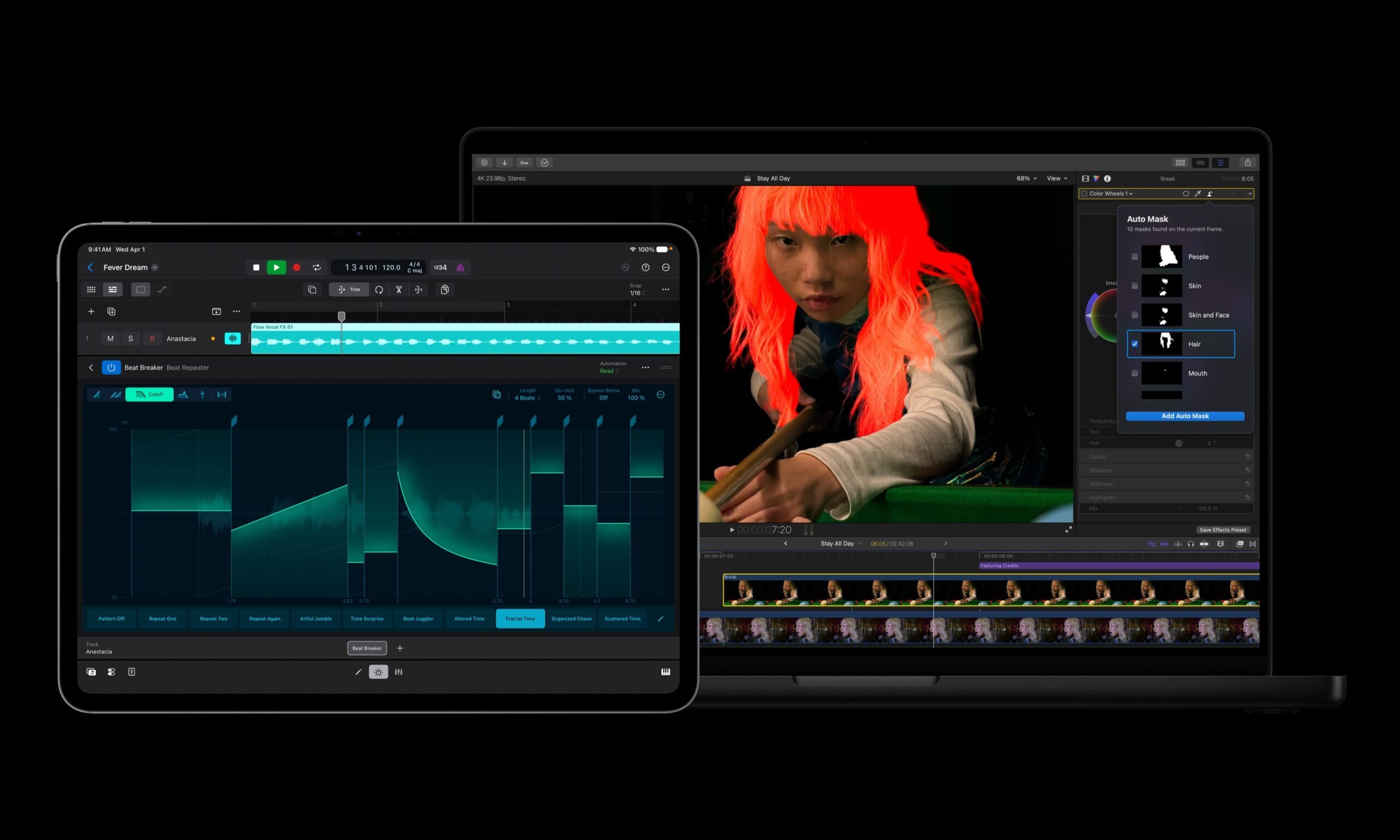
Apple Creator Studio adds AI tools across Final Cut Pro, Logic Pro and Pixelmator Pro

AI browsers like Perplexity Comet can be tricked into spilling your password through BioShocking exploit
Google Play’s latest speed boost goes way beyond the phone

Peacock Premium Plus joins YouTube as the streaming bundle battle gets messier

OpenClaw lands on Android and iOS, turning your phone into a control hub for your AI agent
Gemini will now take notes for you in Google Meet for you, if you the minimum $20 AI tax

After iPad Pro and MacBook Pro, the iMac could be the next in line for an OLED screen upgrade

This $1,299 gaming PC wants to be a Steam Machine without waiting for Valve

This cheap Steam Machine clone sounds too good to be true because it probably is

A YouTuber 3D printed an entire outfit, but the comfort and cost are more complicated than you’d think

The memory crisis isn’t going to ease, and you will pay the price for it, says a research firm

Apple’s next Mac Studio could get a new M5 Ultra chip and a cooler upgrade

Apple’s historically high tax for RAM upgrades on Macs has now become absurd

Windows 11 is getting a new Screen Tint mode, and your eyes might thank Microsoft

Apple’s looking at a politically radioactive fix for the memory crisis, and the US government isn’t happy about it

As iPads get pricier, Motorola’s Pad 70 Pro arrives as a solid option… just not for US buyers yet

The refurbished MacBook Neo may be your best way around Apple’s price hike
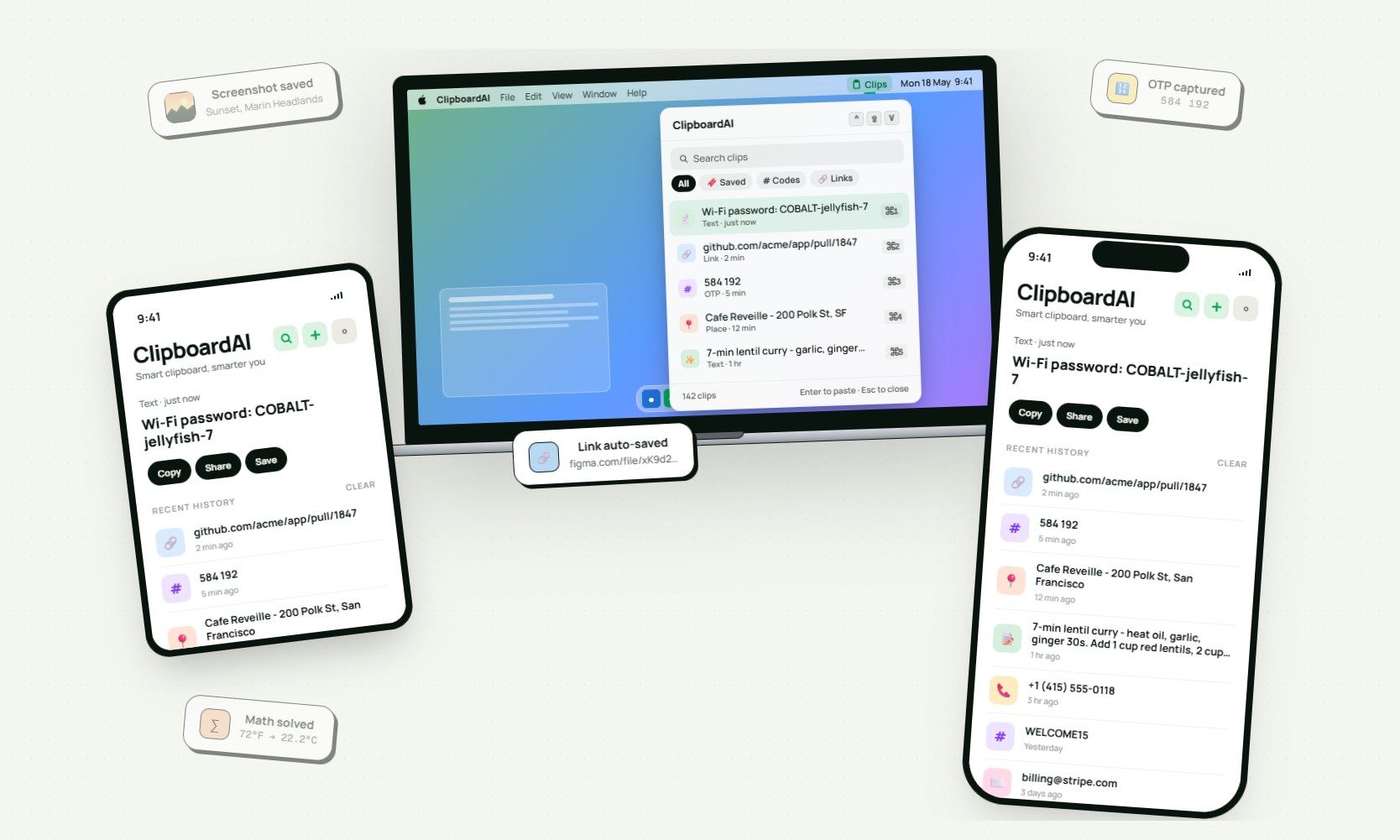
This cross-device clipboard app solves the copy-paste problem I keep running into on my Mac

If you miss the feel of paper in the digital age, this app gives your Mac’s screen a textured look

I dug these last-hour Prime Day smart home, laptop, and accessory deals that are irresistible
Computing News



Laptops






Artificial Intelligence



Computing Guides







