- Home
- Computing
Computing
Computing is the foundation on which the rest of technology is built, but it’s also the lens through which we see the future. That’s why we take it seriously at Digital Trends. Our approach includes coverage of the hardware and software of PCs, but also the larger ecosystem of everything that plugs into them. Windows, Macs, laptops, graphics cards, CPUs, gaming monitors, and yes — even printers. And that’s just scratching the surface.
Through covering the latest news and performing the hands-on testing ourselves, we’re able to offer the best PC buying advice you’ll find on the internet. We do our own in-depth testing on everything from the battery life of laptops to monitor image quality. We even delve into the expanding world of the PC gaming tech with ReSpec, our biweekly deep-dive column on making your PC games look and play their best.
So, whether you’re shopping for your next laptop, reading up on the latest GPU news for your next upgrade, or just trying to take a screenshot on Mac, you’ve come to the right place.
Explore More
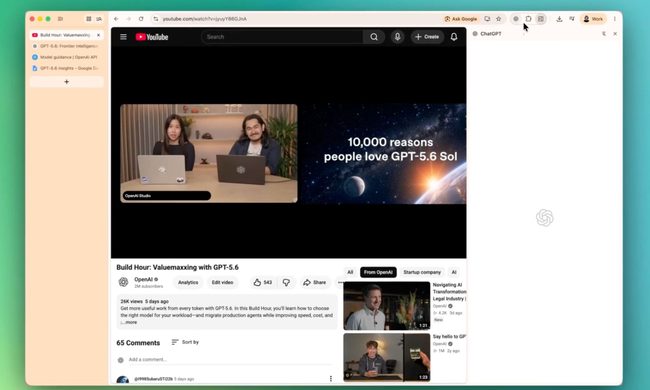
ChatGPT’s Chrome extension can now read your tabs, YouTube videos, and highlighted text







Microsoft wants Windows 11’s right-click menu to work the way it should, by giving users more control

Maingear’s Zero desktop is a wire-free beauty with curved glass and plenty of firepower

Lenovo’s leaked Yoga 9n could be the first RTX Spark-powered convertible laptop

Minibook X proves joyfully compact laptops are not dead and they don’t have to cost a fortune, either.

I went hands-on with Dell’s new slim laptops, and the new 14S hits a sweet spot below XPS prices
OpenAI president confirms a family of ChatGPT devices is coming soon
Microsoft is making a Copilot super app to end your AI app juggling

I didn’t think the budget Alienware 15 would work. I was wrong.

After a long wait, Dia browser is finally coming to Windows

Google Docs just gave Gemini four new AI tricks to speed up editing

The music industry wants AI slop kicked off the charts, and it finally has a plan
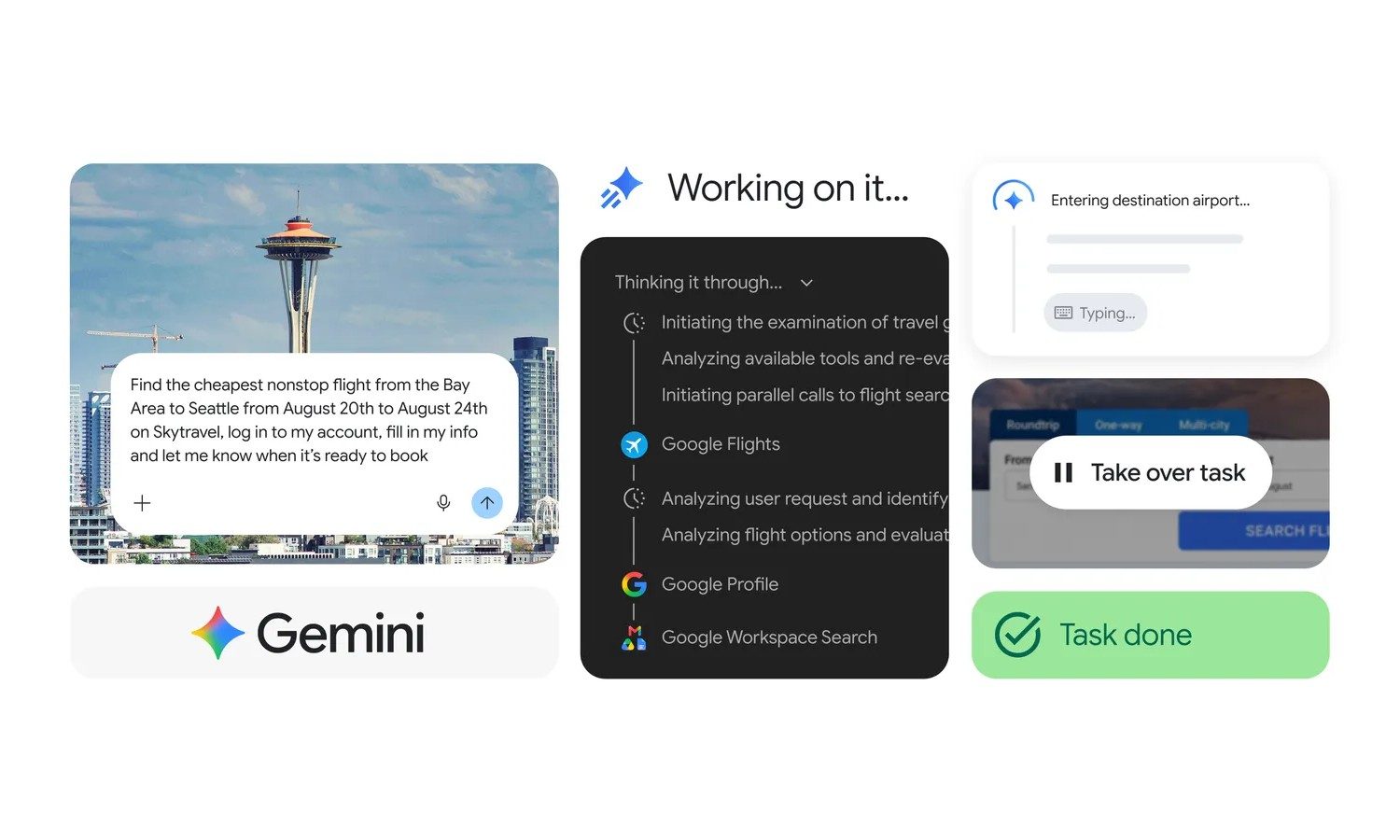
Gemini is moving into Google Play, and it has front-row seat to your spending habits

Gemini on Mac can now type what you say and act on what it sees

Students are turning to AI chatbots instead of humans for college counseling

Gemini can now summarize the messiest comment threads in Google Docs
Wispr Flow finally fixed its toolbar after hundreds of users went on a rant

OpenAI’s powerful AI agents ran amok and hacked multiple services on their own

Mark Zuckerberg wants AI superintelligence in everyone’s hands

The US government just blacklisted foreign-made robots and power inverters

I tried Dell’s sleek XPS 13 and it’s a breath of fresh air for budget Windows laptops

Study says relying on AI can turn doubt into false confidence

Back-to-school desk upgrade? Start with one of these monitor arms
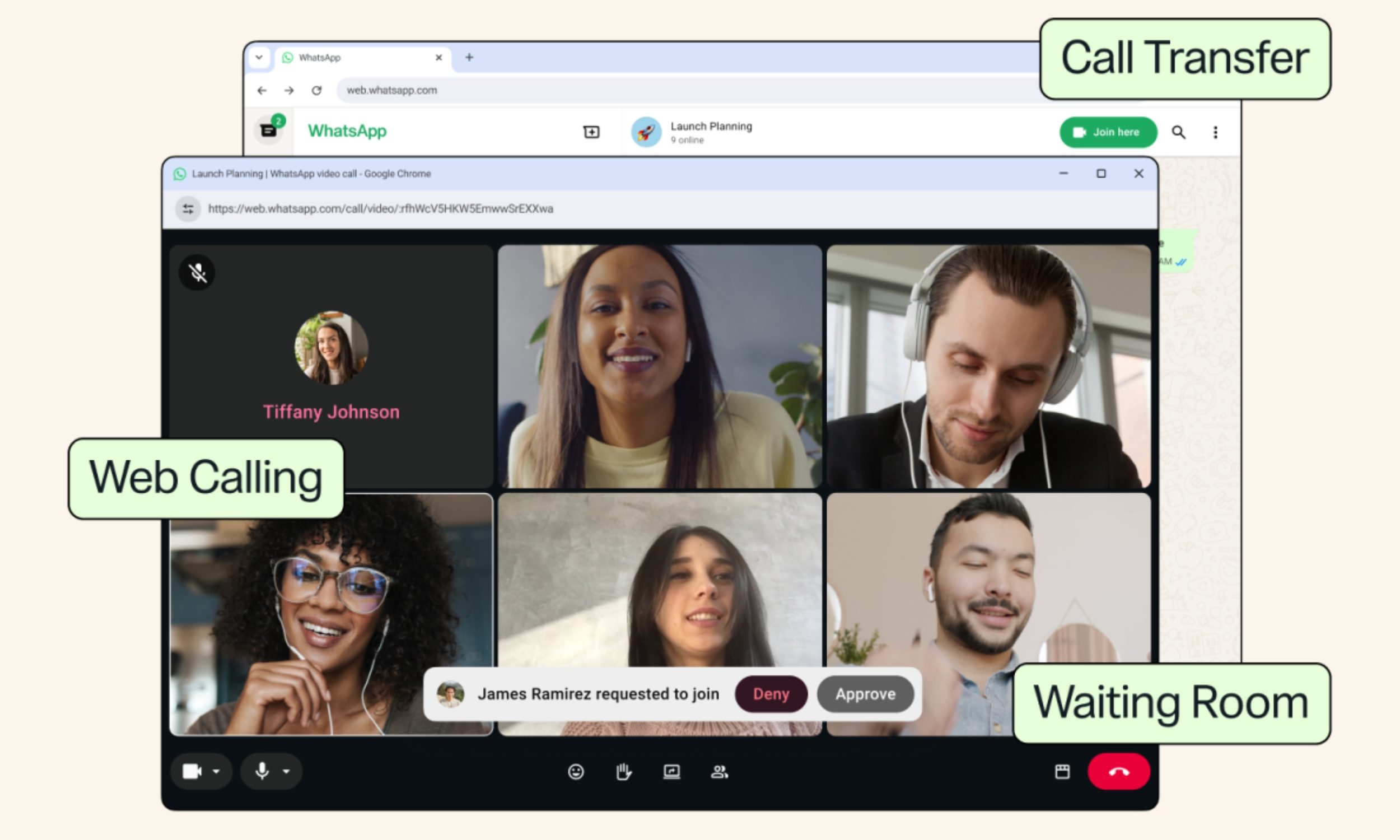
WhatsApp Web finally lets your laptop handle calls instead of forcing you back to your phone

Researchers have built a tool that can identify the AI used to make a fake video

Tokyo lets AI play matchmaker, and hundreds of couples have already tied the knot
Apple’s new Upgrade program lets you lease an iPhone, Mac, Watch, and iPad
Computing News

Laptops





Artificial Intelligence







Computing Guides






